
Which transcription or translation model is best for my language or for my needs? Can I trust the machine to do this well?
The BBC is one of countless organisations in the media and beyond to explore such questions, as machine learning (ML) solutions for multilingual communications appear increasingly viable. At BBC News Labs we have been experimenting with various transcription and translation models for over a decade, witnessing the impressive leap in quality and the number of languages covered by commercial and research-led models.
Translation and transcription models regularly help people navigate simple interactions in a foreign language or conduct certain business transactions. But is their output good enough, and fast enough, to be worth a journalist’s time and attention in a fast-paced newsroom?

I dare not suggest that journalists might trust the output as provided. (Since when does journalism involve trusting anything at face value?) As much as I, a journalist and translator, am rooting for output to achieve such levels of excellence, machine translation and transcription is yet to fulfil its promise, particularly in the so-called under-resourced (read: less common) languages. For a global public media organisation like the BBC, where accuracy is sacrosanct, the bar for acceptability criteria is at its highest, and the penalties for inadequacy at their harshest.
Nevertheless, output in some widely spoken languages can offer benefits for research or for monitoring, with the caveat that, as with any source material in journalism, it needs rigorous checking and scrutiny.
So, is the process of post-editing machine transcription/translation output, i.e. reviewing, checking, correcting, and stylistically-enhancing it, more practical and efficient than transcribing/translating it manually, from scratch?
And once a model’s output in a particular language surpasses the baseline expectations of quality, time and cost, how and where might it be used by a particular BBC team?
To offer an insightful response to the questions above, we at News Labs devised an assessment in cooperation with the BBC World Service and the European Broadcasting Union, whose groundbreaking work created a shared flexible multilingual news platform for public service broadcasters.
This is how we did it.
Results in Plain English please
BBC World Service (WS) journalists work across multiple media platforms and their news sources are often in English, as well as their respective output languages. A lot of news content is transferred across languages through degrees of reversioning, localisation or rewriting. The journalists’ goals and relationship with their source and target material are distinct from that of a translator. A singular translator job function does not exist, and many WS journalists or teams will say they ‘do not do translations’. Any assessment of transcription/translation solutions needs to reflect journalists’ requirements from the output, as they are the intended end-users of our solutions.

From a functional perspective, the mainstream methods and metrics of transcription and translation evaluation are often cryptic – at worst irrelevant – to a journalist or editor.
For transcriptions, the most common method to gauge accuracy is word error rate (WER) – the proportion of words a model gets wrong in a sample. For a 1,000-word sample, if 100 words are incorrect then the WER is 10, and the success rate 90%. In our experiment, our evaluators often assigned a success score of 60% to a sample with this many errors.
However, not all errors are of equal severity; missing a comma is not as severe an infraction as missing a key word that could distort meaning, spurring a healthy debate on how to instil more subtlety into WER.
With transcriptions, the ‘reference’ or ‘ideal state’ of the output is in the same language, perfection is therefore achievable and testable. Whereas translation is a subjective art, where a single ‘reference’ is elusive.
For the smart people developing translation models, the mainstream route of evaluations is algorithmic calculations. These methods/metrics, evolving in tandem with the models, have poetic names such as BLEU (BiLingual Evaluation Understudy) rising to the interstellar, such as METEOR (Metric for Evaluation of Translation with Explicit ORdering) and COMET (Crosslingual Optimized Metric for Evaluation of Translation). In the simplest terms, they measure quality in terms of how close a machine's output is to that of a human by comparing output with reference translations, with results ranging between 0 and 1 (higher = better).
Nevertheless, telling a news editor that English to French output now scores 0.809 would mean little. We needed to translate translation benchmarking results into plain English; how good are the results, how grave are the mistakes, and how long does it take to make it ‘usable’?
To add another layer of complexity, news translation is less concerned about preserving form, compared to conventional modes of translation. Scholars of news translation increasingly define output as a “new or redesigned offer of information”. While factual accuracy remains paramount, the order and expanse of information can vary; and stylistic loyalties sit firmly with the target culture and language.
So we went back to basics and devised a functional model of human evaluation based on conventional benchmarking: measure and compare the performance of competing models for intended uses.
We tested several household names in translation and transcription, including AWS, DeepL, Deepgram, Google, Microsoft Azure, Speechmatics, and OpenAI’s Whisper.
We focused on Arabic, French, Brazilian Portuguese and Spanish since these are some of the languages where models are at their most mature, and the BBC has large teams with multiple outlets operating in these languages.
This work was made possible thanks to the BBC’s unique richness and complexity: its highly skilled and diverse workforce. The BBC’s news headquarters in London houses not just an amazing array of journalists broadcasting in 43 languages, they are wordsmiths and craftspeople: linguists, translators, poets and authors, recognised in their own right. We were fortunate to cooperate directly with their in-house expertise, where each of the language teams nominated evaluators trusted for their language skills as well as their editorial judgement.
45,000 words evaluated per language
The nominated journalist-evaluators were asked to check, correct and appraise content, split into three packs, to a state they deemed “usable”, with no factual errors:
- Transcriptions in their language
- Translations from English into their language
- Translations from their language into English
For the latter, we asked evaluators to focus on factual accuracy, dialling down any style considerations, to homogenise stylistic expectations based on their individual proficiency in English.

To create conditions as close to reality as possible, we compiled a selection of BBC News content either broadcast or published across various subject areas or genres.
Each of the three task packs included 10–12 samples. Each text sample in the pack was approximately 1,000 words long – an average-length article. The audio/video extracts were six to seven minutes long (1,000-1,300 words). By the end of the assessments, each evaluator had reviewed 15,000 words for each of the three tasks above, amounting to approximately 45,000 words per language.
For translations from English, all languages worked from the same source samples. For samples into English, they were like-for-like. We were mindful that the vocabulary and level of linguistic complexity of a story about elections, a space experiment or a personal narrative would not be uniform. Each model’s success could also depend on how much similar content it had been exposed to in the original training data.
Furthermore, a written account, a recorded interview, or a live conversation with an eyewitness are structurally different and offer varying levels of complexity, too.
Assessment packs therefore had an even distribution of genres across text and audiovisual samples. These included news bulletins, political analysis, economic explainers, science and health stories, societal issues, all topics which feature in routine programming. Sections that were particularly challenging or simple were removed to ensure uniformity within – and across – samples. Each sample was then processed multiple times by various models.
Our goal was to ensure that at least three samples per task were processed by every available model, while the remaining samples gave each model a fair distribution across genres and topics.
The assessments were conducted offline. The evaluators did not have to interact with a new, unfamiliar interface. They timed themselves as they reviewed and corrected the content, and all corrections were tracked on the document. When finished, they assigned each sample a quality score between 0–100.
The scoring brief to the evaluators was not to seek perfection, but consider what they might reasonably expect from a sharp, fresh graduate starting a work placement: a body of text with no major errors, but some minor ones, and might need stylistically refining to align with the BBC’s content.
Evaluators then went over the material a second time, to categorise and colour code their corrections into one of the following categories:
- Major errors: a serious error that alters the meaning in a way that’s misleading, or factually incorrect
- Minor errors: an error that does not cause a misleading result, but which needs correcting to be usable (including capitalisation, punctuation, spelling of well-known people or places)
- Stylistic enhancements: things that were corrected since they reeked of a “literal translation”, or cases where the wording or use is different from the accepted phrasing that’s expected from the BBC language team’s output (such as how numbers or currencies are written)
- Imposed (transcription) errors: Only applicable for audiovisual (AV) samples for translations, this refers to issues that arise from errors in the preceding transcription that acted as the source text
The evaluators took notes of where things seemed to go wrong, and whether there were any recurrent patterns in errors.
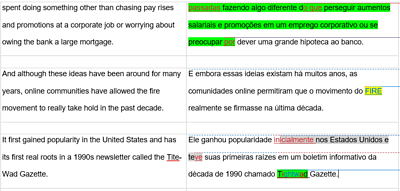
We also assessed and compared transcription samples from nine models in English. The results suggested that adopting the best performing models could achieve significant improvements in quality, as well as offering savings in both time and cost compared to models that are currently available to journalists at the BBC.
Then came the long, manual process of grouping categorised errors, adding them up and averaging scores per model, as well as the time it took to complete the process per 1,000 words. We ranked the models based on the highest score, the least time required to revise 1,000 words, and prioritised those with the fewest “major errors”. Our final shortlist comprised the top two models for each language.
This particular assessment, despite being one of the most comprehensive of its kind in news, was conducted with a pre-selected set of samples, processed offline. The scoring practices reflected the expectations and preferences of individual evaluators. For instance, one evaluator’s scores for a sample with 10 errors were consistently lower than another’s, who was more lenient. A future iteration that applies more specific guidance on scoring, and assigning weights and penalty points to more error categories, would offer further insights.
Key impressions
The exercise corroborated our expectations: there is not a single provider which offers the best solution for every language across the board.
Output in/into English is still significantly ahead of other languages in quality.
And there is still a considerable gap between the higher quality of text-to-text translations, and how well audiovisual material can be translated due to the fact that speech is inherently less structured. This causes an exponential increase in errors when transcription and translation are combined back-to-back, without a correction stage in-between.
While models are improving, there still appears to be a lag in the rendition of text, particularly in transcriptions. Issues include segmentation, capitalisation, punctuation (including the accurate placement of commas, full-stops and quotation marks), abbreviations, numbers, currencies or accurate identification on the basis of context (e.g. blue print or blueprint, tyre or tire; 2 or too).
Nevertheless, we found that working with the ‘best’ models can save considerable time.
Processing and correcting transcriptions are four times faster than a human can deliver. On average, the manual transcription of a six-minute clip in English takes around 30 minutes. With a robust model, it can take as little as six minutes to review and make all corrections (or even less if the reviewer increases the playback speed).
Translations, particularly between languages of proximity (such as English–French), also cuts delivery time by a third. This could allow journalists to move further away from mundane typing tasks and focus on more value-added journalism.

When we compared our rankings with rankings based on algorithmic results (calculated with BLEU/Chrf++, TER and COMET), it was reassuring to see that they strongly correlated in terms of which models were considered best for each language.
We shared the results with the teams alongside a recommendation to conduct a round of trials focusing on the two best models for each task, and gather more detailed feedback from a larger set of evaluators and samples. News Labs is currently building the interfaces required to support, monitor and measure this trial stage.
Pairing quality levels with recommended uses
The assessment sought to identify where a particular model’s output in a particular language might sit on the axes of “translation adequacy and acceptability”. Minimising major errors would imply the text conforms to its source text, ensuring “adequacy”. Whereas the extent to which the output is a stylistically authentic representation in the target language would shift the dial towards acceptability.
Adequacy is the bare minimum to employ these models in the context of journalism’s monitoring use case: being able to follow a story accurately from a source in another language. This would instantly remove language barriers between BBC World Service’s individual language services for better discovery, analysis and collaboration.
Adequacy is also generally sufficient for using translation as an enabler. Here, translation works as a stepping stone for semantic processing methods that are unavailable in the source language but available in a larger language like English.
For example, by translating World Service news articles in various languages into English, News Labs could link and cluster World Service language teams’ articles to measure the scale of a particular story’s impact across multiple languages. Likewise, News Labs used translations for matching pre-approved graphics with text in more than a dozen languages back in 2021.
Finally, the content creation use case involves revising and correcting machine output through human post-editing and editorial approval processes. This type of workflow would support production efficiencies and allow teams to reach audiences beyond their own.
These evaluations offer a functional snapshot and a tentative indicator of the perceived quality of machine translation/transcription output, rather than an absolute result. We expect this work to pave the way to further rounds of evaluations in other languages and we may apply a more a detailed categorisation of the error types and introduce a method of automating the calculations.
Nevertheless, by formulating a functional assessment to be conducted by journalists based on news content, we have evidenced these models’ extent of usability for genuine workflow scenarios.
We designed our method to ensure the results and scores are transparent, understandable and open to the scrutiny of editorial decision-makers and enable editorial teams to have an accessible, informed discussion about the comparative quality of the different solutions, the common pitfalls, and the pros and cons of utilising such models for certain, internal use cases. What remains beyond doubt is that any output will need robust human oversight for the foreseeable future.
News Labs will continue to explore how the best practices of such oversight can be ingrained in workflows. A validation pipeline to ensure optimal accuracy, a method to assign quality scores to output within editing tools and a means to assess contextual and editorial amendments as distinct from the linguistic enhancements would all proffer stimulating experiments.
We would love to hear from others working in this area to compare notes and discuss the challenges we are all facing. Contact us at newslabs@bbc.co.uk
See more of News Labs multilingual projects
Latest news
Read all newsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



