
Often it's the tasks humans do without thinking that require some of the most complex processing behind the scenes. Tasting food, chatting with friends, listening to music and, indeed, recognising people. When you watch an episode of Eastenders, you see the different actors in different settings, from different angles and in different lighting, but instantly your brain handles these variations to know that it's Dot Cotton and Phil Mitchell in the scene. Because we don't think about the processing involved, we're surprised to find that these tasks are much more complex than we initially thought when we try to apply them to machine learning.
Take the following images from Prince Harry and Megan Markle out on the street. We can see Harry and Megan from different angles here - front, side and back - yet we easily recognise them from their features: skin colour, hair colour, and so on. We're also taking certain social cues into account. The crowd is looking at them, they're well dressed, they're in the centre of every shot and there's an obvious continuity of shots being from the same scene. There are many layers of human intuition here we tend to not even think about as we detect cultural as well as physical indicators.

So how do we teach a computer to learn to do all this? While we can't get an algorithm to think like a human, we can get it to do what machine learning does best: detect patterns in large, labelled datasets. This involves collecting images, training the algorithm, processing videos and recognising the people in them. The final output is a list of people recognised in a video along with the time and location in the frames they appear.
We're already working to build this technology at the BBC. Our system, called FaceRec, is being developed by the Internet Research and Future Services Data Team within BBC Research and Development (we'll save some keystrokes and just call them the Data Team from here on out). It's built using a combination of in-house code and external open-source software - particularly, Seetaface, a C++ facial recognition engine.
FaceRec works by processing video through a series of algorithmic steps, each solving a specific part of the overall problem. We'll give you an overview of how it all works.
1. Detect shots
For each face to be detected in a video, we first need to break the video up into its constituent shots (a shot is defined as a series of frames running for an uninterrupted period of time). To do this, FaceRec uses the media processing library FFmpeg, which uses a function to return all shots' start and end times within a given video.
2. Detect faces
The next step is to check each frame to see whether it contains human faces. This is a tricky problem - should we try to detect every single face at a football match? Does a face on a t-shirt count? Do photos on the front of newspapers?
Iterating through each shot, FaceRec takes frames from the shot and feeds these to SeetaFace, which then returns the bounding boxes of where it thinks the faces are. SeetaFace's face detection engine discerns whether a face "counts" enough to include in its output. Please note that SeetaFace is not saying who it thinks the detected people are, merely that it believes that it has detected a face in a given location within the frame.
3. Create face tracks
Now that we've collected all the frames containing faces, the next task is to stitch these detected faces together to create a face-track. A face-track is a continuous flow of bounding boxes around a face as it moves within the shot frame.
FaceRec takes each face bounding box and tries to map it to the next logical bounding box in the following frame. This is not always entirely obvious, as faces can be temporarily obscured or bounding boxes can cross each other as one person moves behind another.

Under the hood, this problem is solved by using Dlib and the Lucas-Kanade method. This creates face-tracks which are defined by time-points, a list of frames and the bounding boxes of the faces.
4. Create face-vectors for tracks
Machine learning algorithms often work by converting input material into mathematical vectors. They then learn which parts of this "vector space" belong to specific categories or input types. In terms of faces, they would learn that vectors representing Prince Harry's face tend to be in a particular area, while Megan vectors tend to be over in a different section. You would also expect vectors of Prince William's face to be closer in this space to Harry than to Megan, since they're related and share similar characteristics.
To create vectors for the detected faces, FaceRec uses SeetaFace's face identification library. FaceRec feeds in cropped photos of the detected faces within their bounding boxes from the mid-point of the face-track. It receives back a 2024-dimensional vector that represents the features of that face.
5. Recognise people's faces in face-track vectors
We now have a face-vector for each detected face-track. The next step is to turn these vectors into the actual names of the recognised faces, as well as flag the faces we don't recognise (and therefore can't label).
The first question here is: just who do we recognise? We surely can't build a model to recognise everyone who's ever lived - and nor would we want to. So who do we deem important enough for this face recognition system?
Realistically, this needs to be driven by the journalists in BBC News and the people they most commonly report on. We also need be aware that unknown people make the news every day, and when they do, we may not have any previous pictures of them. With these limitations in mind, the Data Team focussed mainly on celebrities, international leaders, U.K. politicians in Parliament and the House of Lords when training FaceRec.
To recognise these people, they needed to gather training data on each person - that is, plenty of labelled photos of that person containing only that person. The Data Team collected thousands of photos and then built their own front-end system to easily view and label individual photos. The unsexy truth of machine learning is that collecting quality, labelled data is often the most expensive, laborious and yet important part of building a well-functioning AI system.
Having collected the photos, the Data Team then fed them into a machine learning classifier called a support vector machine to create trained models. When fed a face-vector from SeetaFace, these models predict the name of the person in the original face image or say whether they didn't recognise the face at all.
IRFS created two models:
Archive model: Famous people from the 20th century onwards selected by people from BBC Archive. This model contained roughly 1,000 people.
News model: Still in development, this will expand to include over 2,000 members of the UK Parliament and regional assemblies, the House of Lords and global leaders. Training images were sourced from BBC News, Factual and Drama.
These trained models are then used to predict which people are in the face-tracks in videos.
6. Cluster face tracks
Now that all the face-tracks have been labelled, the final step is to collect all of the tracks of the same person.
To do this, we put all of a video's extracted face-vectors into one vector-space, which we'll call a face-space for fun. To visualise the face-space we can use a tool called Tensorboard, part of the machine learning library Tensorflow.
Looking at this face-space, we hope that vectors from the same person are close enough together and far enough away from other people that we can automatically group them. This is known in machine learning as a clustering problem.
We can see the face-track vectors projected into this face-space for the Harry and Megan video below. And we see that most of the Megan tracks are bunched together, making them easy to cluster. That's one way we know that the face vectors created are working well.
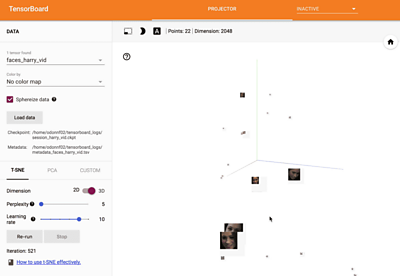
Those familiar with clustering will see the difficulty of our face-clustering problem. For every video, there will be a varying number of clusters of varying sizes - with plenty of vectors appearing once and belonging to no cluster at all.
Instead of falling down a dark hole by trying to perfectly solve this problem, the Data Team decided to run with a few heuristics. FaceRec splits the problem up into two separate categories: faces of people it recognises and faces of people it does not. For recognised faces, it simply clusters all face tracks together that have the same predicted label (name). For unrecognised faces it uses a technique called hierarchical clustering over the face vectors to group them, but not give them labels.
7. Output the info
The last step for FaceRec is feeding out all of the information collected throughout the different steps. This comes in the form of a JSON file which contains:
- A list of tracks in the video. For each track it has:
- Predicted person for that track
- Confidence of the prediction
- Track UUID
- Face-vector for that track
- List of frames in that track
In the list of frames, the info on each frame includes:
- Face vector for that frame if it has been detected
- Bounding box coordinates for the face
- Time in the video the frame occurs
What can we do with this data? You can check out our next blog post to see our ideas.
Wrap-up
That's about it really. Hopefully we've helped you understand the many parts that go into a video face recognition system. And perhaps we've also made you more conscious of all the heavy lifting and ambiguities your own brain handles hundreds of times a day when recognising your friends and loved ones.
After understanding the inner workings of the FaceRec system, the task for News Labs was to see where this technology could add business value within the BBC. How do we show off FaceRec's abilities with an intuitive demo? Which production systems could we see FaceRec fitting in to? Whose workflow problems could it solve? And importantly, how do people feel about using face recognition? We talk about the challenges of rolling out a new technology within a large organisation and the questions we faced when developing a facial recognition prototype in "Face Recognition - What Use is it to Newsrooms?".
Latest news
Read all newsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



