

As a third-year broadcast engineer apprentice, I was rapidly approaching my final dissertation placement. It was going to be a bigger undertaking than anything else I’d worked on. I was fully responsible for planning and managing a project that would be useful to the broadcast industry. Not only that — it would also make up a large proportion of my final degree classification.
With a lot riding on my choice of topic, I was relieved to run into Andy Secker, BBC News Labs’s language technology lead, at a beer festival, who had supervised one of my previous projects.
Andy had an idea that needed an investigator: whether or not the BBC’s transcription service could process audio content faster by harnessing the scalability of cloud computing technologies.
Is there a better way?
BBC News ingests a large amount of content every day from around the world. Previously, this meant that journalists spent a lot of time playing back audio and video clips within our media asset manager to find shots for their stories. Nowadays, the BBC is piloting speech-to-text to transcribe incoming news content, allowing journalists to search for audio and video files with keywords instead.
Kaldi, our speech-to-text system, aims to transcribe content as soon as it arrives in the newsroom. But it has to process files coming in from multiple ingest queues and handle an ever-growing volume of content, which has led to large delays between a file arriving in the newsroom and the finished transcript.
In order to improve this latency, a simple solution is to spread incoming transcription jobs across a larger number of workers. Cloud computing makes this sort of horizontal scaling easy, but we wondered: is there a better way?
Our existing workers can transcribe content in roughly real-time, meaning that a ten-minute video will take roughly ten minutes to process. So here’s the idea:
What if we split the incoming file into small audio chunks and transcribe them simultaneously, collating the results at the end to form a single transcript?
This theoretically means that processing ten equally-sized (i.e.one minute-long) chunks of the ten-minute file would take roughly one minute, not ten. The shorter the chunks, the lower the total processing time.
This sounds like a great idea, but we guessed that it would also decrease the accuracy (or, to put it another way, increase the word error rate) of the transcription, for the following reasons:
- The file may be split in the middle of a word, either losing that word entirely from the transcript or resulting in an unwanted word substitution.
- Our speech-to-text engine uses word context to improve accuracy in the transcription. Splitting the file will lose context for the words nearest to the split points, increasing the word error rate.
So it’s clear that there is a tradeoff between the length of an audio chunk (shorter is better in terms of transcription speed) and the accuracy of the final transcription.
There might, however, be a solution: the use of a diarization algorithm to segment an incoming audio file. The purpose of a diarization algorithm is to identify unique speakers within a piece of audio, but it can also be used to segment the file. Because it has data on who is speaking, it can split the audio when a speaker pauses between sentences, or one speaker switches to another. Using a diarization algorithm should eliminate the two issues with fixed-length chunking because the algorithm should never split the file in the middle of a word or sentence.
That left us with two questions to investigate:
- When using fixed-length audio chunks, what is the effect of reducing the chunk length on the word error rate of the transcription?
- Does a diarization algorithm maintain or reduce the word error rate of the transcription when it segments an audio file into smaller chunks?
System architecture
Conceptually, the system architecture was straightforward. A single worker split the incoming file into chunks, which it then sent to a set of transcription (Kaldi) workers. These scaled automatically depending on the number of audio chunks they received from the split worker.
Each transcription worker then delivered its completed transcript to the collate worker. When the collate worker received all sections of the transcript, it merged them and passed the full transcript back to the user.
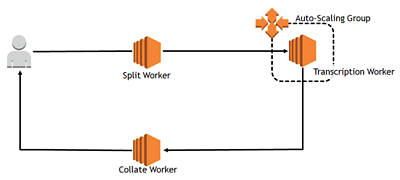
For our tests, we used BBC’s Kaldi transcription engine and a dataset from the Multi-Genre Broadcast Challenge 2015, which includes over 11 hours of mixed audio recordings. The dataset’s files each come with a manually-produced transcript, so we could set a baseline word error rate by running all of the audio through Kaldi without any chunking. We used this as a reference point for our chunking tests.
Fixed-length chunks
The simplest way to speed up our Kaldi transcription service is to split incoming audio into equal fixed-length chunks and transcribe each chunk separately:
The chart below shows the difference in the word error rate from the baseline (the rate we got by running unsegmented audio files through Kaldi).
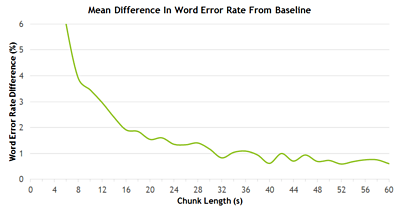
As we predicted, the longer the length of the chunk, the smaller the increased word error rate. With audio chunk lengths longer than 40 seconds,the transcript word error rate is consistently within 1% of the baseline.
Diarized chunks
Next we performed the same test, but using the LIUM diarization algorithm to segment the audio files. This resulted in two significant differences from the fixed-length chunking:
- The chunks were of uneven length
- Areas of music, silence, or other non-speech were discarded
Eliminating non-speech sound makes the whole transcription process more efficient by cutting down on the amount of audio that needs to be processed. When we used this technique on our test data, the chunks generated by the algorithm represented approximately 08:47 of audio — 21.7% less than the duration of the unsegmented clips.
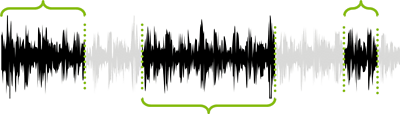
The algorithm produced chunks that were an average of 6.64 seconds long, with 24.93 seconds being the longest and 1.01 seconds the shortest. The distribution of chunk lengths can be seen below.
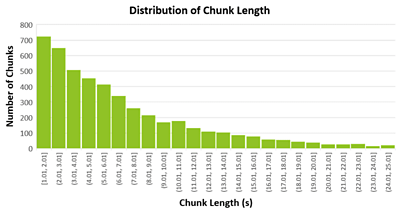
The results
We had to make some assumptions to evaluate our results. The first is that we can scale the transcription workers without limit: no matter how many chunks we create, a worker will be available to service the request. Secondly, we ignore any extra time it takes to start new transcription workers and get Kaldi running when measuring transcription speed. Since these are the same for both approaches, we didn’t need to account for them to compare the two.
We can now determine the difference in accuracy between this diarized chunking approach, the baseline, and the fixed-length chunking approach.
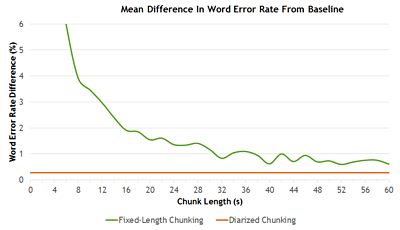
When diarized chunking is used as the pre-processing step, the accuracy is maintained even more so than when using fixed-length chunking. There was a mean difference of just 0.28% increase in word error rate over the baseline — even though the average chunk length was less than seven seconds.
The solution is clear…
The purpose of our project was to see whether it’s possible to split an audio file into many smaller chunks and transcribe them in parallel to speed up the overall transcription process. Importantly, the methods we investigated need to maintain the same level of accuracy that journalists expect when using the BBC’s current system, which transcribes audio files as a whole.
Splitting the file using the LIUM diarization algorithm seemed to meet all of our criteria. The accuracy of the final transcript was close enough to the baseline for us to consider it equal. Even though the speed of the different workers’ transcription is limited by the length of the longest chunk, the biggest chunk the algorithm generated for our test data was 25 seconds — still significantly below the 40-second chunk length needed to get a reasonable difference in accuracy between a fixed-length chunk and the baseline.
Or to put it another way: we could, in theory, transcribe all 11 hours 13 minutes of test data in just 25 seconds using a diarization algorithm, with no noticeable increase in word error rate.
The solution is clear then?
Maybe not — and this is due to the extra time it takes to pre-process the audio files using the LIUM diarization method. The time taken to diarize and split the files within the test set was found to be, on average, 154 seconds. This is compared with 0.4 seconds to split the files for fixed-length chunking.
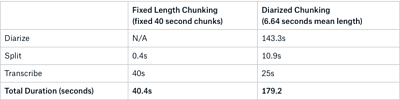
So yes, the solution is clear, but it is not the one we expected. Using fixed-length chunks of around 40 seconds in length would allow us to process an audio file in just over 40 seconds in total. This contrasts with an average time of 179 seconds for diarized chunking, consisting of 154 seconds (mean) for diarization and splitting followed by 25 seconds of processing.
While we conclude that the full transcription process is always faster if the audio is split by fixed-length chunking, we believe that we could continue exploring diarized chunking — this time, with a different algorithm. LIUM was last updated in 2013. Could there be a more accurate and, crucially, faster diarization toolkit available now?
We’re leaving that to a future broadcast engineer apprentice to investigate.
This project relied on the work of Matt Haynes and BBC R&D’s IRFS team, who provided insights into the speech-to-text process.
To find out more about the BBC’s Broadcast Engineering Apprenticeship scheme — and our other graduate and apprenticeship schemes — please visit the BBC Academy website.
BBC News Labs wishes Kurtis the best of luck at his new role at BBC TV, Radio & Archive Engineering.
Latest news
Read all newsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



