
Best fit imagery
We always aim to lower the workload on journalists so they can stick to story creation. To achieve this, we experimented with a range of tools to automatically add images to the comic panels, based on the text entered.
We used entity extraction to pull out key words and phrases, before using fuzzy matching to find a range of possible suitable graphics from our image bank.
The comic was automatically populated by imagery with a high confidence. When the confidence score was lower, we presented journalists with a range of options.
Verdict: Success. Journalists liked the auto-population, but not all panels had an auto-populated image. This could be improved by building out the relatively small bank of images used for the experiments.
We wanted our content to be engaging, so we discussed working with different language types, colours and design patterns.
One idea we tested out was basic animation to assess the difference between static and dynamic comic panels. For social media users, we thought these may feel familiar as a GIF-like experience.
There are risks however. We have found in previous user research that it is possible to turn off audiences, through experiences they view as gimmicky.
Verdict: Further testing still needed.
Image segmentation
The main drawback to using a finite number of images was the likelihood of stale graphics, particularly for habitual users.
We hope that populating the image bank using object detection and image segmentation could ensure graphics stay FRESH.


Say we want a DNA helix, we can browse an image library to find one. To make sure we only get the helix (minus the background scene), we use object detection to pinpoint its location and OpenCV to crop around the edges.
You can see the result below.
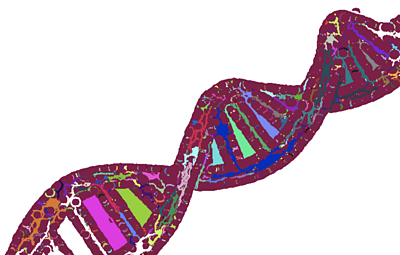
Verdict: This method shows potential.
Lessons learned
There is great potential in a lot of what we have been working on with Graphical Storytelling and certainly scope for future experimentation.
As always, not everything we try works first time. Thankfully user testing, whether with audiences or journalists soon shows us what we need to develop.
Latest news
Read all newsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



