
Often, we decide what is newsworthy based on the latest developments on a story rather than seeking to improve audiences’ overall understanding of important issues.
For journalists this makes the background context problem a big one: don’t explain enough and we lose the reader, explain too much and it feels patronising. There is a sweet spot that explains while moving the story on, but it varies hugely depending on the reader.
Even if we do hit that sweet spot, we have to repeat the same explanations, definitions, or background details on who a person is and what their role is over and over. We do this to make stories on the same topic understandable as events develop over a week, month or even years.
The problem is an acute one for the BBC because of our mandate to serve all audiences. We've been experimenting on ideas to solve this in News Labs for a long time - can we make the news more understandable while saving our journalists from duplicating work?
It’s a huge problem space. To tackle it we’ve broken it down into its two component parts: the newsroom side with its efficiency problem; and the audience understanding challenge which requires personalised information retrieval and rendering at the right time.
The newsroom is not a library
It’s not just the stark contrast in sound levels that differentiates libraries and newsrooms. A library takes a systematic approach to storing and retrieving information in as efficient a way as possible. Books are categorised, catalogued and their location decided based on set criteria before this data is recorded in a way that makes finding the book again easy, no matter how large the library.
Unfortunately, we do not store the knowledge of the newsroom in the same way. There are some closely related concepts, a style guide is a quick reference for journalists that clarifies spelling or the editorially approved phrasing of a contested issue. The BBC style guide is open.
In the world of education technology, information is organised in a systematic way to make it easily retrievable and reusable. BBC Bitesize is structured around the curriculum for example.
The modern equivalent of the librarian’s index card is a search engine, which scrapes the web, indexes it and makes information findable on it.
Ever wondered why Wikipedia pages are often at the top of search results even though news outlets publish verified information on controversial topics that is expertly written?
We publish stories which are structured to lead on the new developments and bury valuable analysis and definitions in them.
This makes these important snippets difficult to retrieve, even when they offer a clear explanation of a complex issue.
Let’s say I’m writing a story that requires such an explanation:
- Most news teams will know where they read a great break down of a complex concept, for example inflation. If it was in a recent story they either search the web or the content management system for it in order to use it again
- Some may find the above option too time consuming and figure they are better off writing it from scratch themselves, even if they have done so ten times before
- Others may not even include the explanation in the story if they feel it isn’t essential
What if we could give journalists the right piece of background information at the right time as they write their story so that they know it’s already been done and they could include that existing block in their new story?
Better still, what if we could provide this nugget of background context for the audience, that one thing someone feels they need to know to get a better grip on a story, at the right moment for them as they consume the news?
These are the two exciting ideas we’ve been experimenting with.
Not another content management system
Our first prototype to solve these problems - called the Explainer Builder - started in 2019.
It requires journalists to create question and answer pairs on the topics they cover and then export them for reuse across published articles as an embed that is not part of the body text on the webpage. The embed also features a search function so audiences can try to find existing answers to their questions based on what's already created in the system.

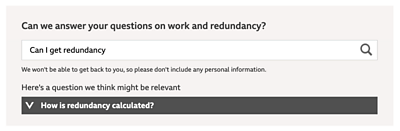
While the embeds produced using this prototype - for example this one on the pandemic's impact on the economy - got a lot of traction with audiences when the questions displayed by default piqued their interest, far fewer engaged with the search functionality.
Even when audiences do have questions on stories - and it is clear that an immediate answer may be available from a news outlet, itself a brand new experience - it takes a higher level of active engagement than traditional news consumption to type those questions. Readers then still have to browse the suggested answers for one that matches their query.
Journalists also found updating answers in a separate system from where they were crafting their stories cumbersome. We also found that there was a high variance in the length and style of the answers in the system. Some were evergreen while others required frequent updating, for example on the fast moving US election primaries last year.
We’ve tried to remove these obstacles in our latest iteration…
WRITING FOR REUSABILITY
ReflEx is a new approach to creating these nuggets of explanatory text, be they short definitions, bios, or simple break downs of complex issues by our expert correspondents.
We’re encouraging teams to keep definitions short, one to two sentences, and then offering the ability to stack these nuggets into longer explanations using a simple referencing syntax.
Our politics team, based in Westminster, started to experiment with this approach by building a set of definitions of processes in Parliament. For example, what is a second reading? Hint: the answer references the definition of a bill.
Other teams at the BBC have started to write small pieces of content in this way, for example our climate journalists worked with editors to produce short explanations of the link between extreme weather events and climate change for use in stories as they break.
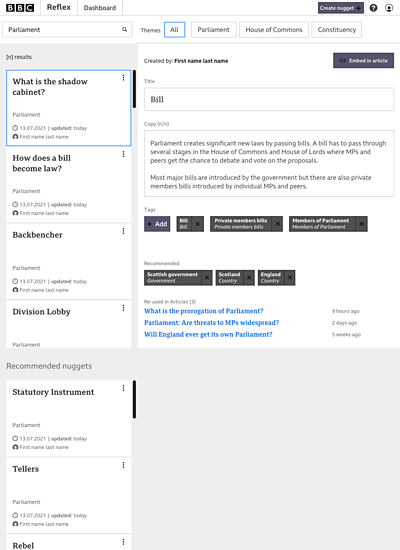
Writing in this abstract way and thinking about how sentences could be stacked to be combined into longer paragraphs and structures that add to audience understanding has some parallels to another News Labs project, Salco.
While those semi-automated stories were written in advance using natural language generation to take shape as data changed, the explanations in ReflEx are written to form blocks of content that shift shape depending on the familiarity of the audience member with a story.
We are therefore experimenting with the concept of having multiple versions of the pieces of knowledge in the system, with the style and length of each one tailored to a specific audience segment.
Keeping the goods fresh
During all of our work in this space, including many conversations with a broad range of journalists, one recurring theme is the expiry of content. In the Explainer Builder prototype, we allowed journalists to set expiry dates on answers and raised alerts when these times passed.
We are extending that concept in our work on ReflEx by not just tracking a date for expiry but also reasons. Examples include when someone referenced in an answer no longer holds their current position, an easy one to imagine being the prime minister, or a political agreement or treaty collapsing or being revoked.
We’ve started to think about where all of this work could lead us next and are keen to explore the semi-automated creation of the content managed in the system, using natural language processing.
Instead of asking editorial teams to create the answers and definitions for this system from scratch, could we extract relevant snippets of knowledge from their existing work and offer those excerpts as drafts to be tweaked for use in this prototype?
Latest news
Read all newsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



