Aims
How might we automatically annotate and chapterise our Broadcast News via the act of captioning?
While the BBC are leaders in Broadcast News quality and craftsmanship, there are still challenges in workflows between digital and broadcast.
This project illuminates some opportunities in making our linear content more discoverable and reusable, by taking captions (aka "lower third", or "astons") and using them to mark chapter points.
How will we use caption data?
- Take captioning speakerID data and timing info.
- Match caption speakerIDs with BBC Linked Data uris
- Build a UX that allows the linear content to be slices and diced according to the speaker of interest
- Use ROT (Record of Transmission) as source video.
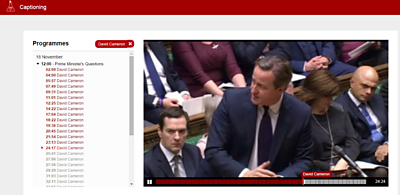
This project extends from the News Slicer project. NewsSlicer uses MOS Running Order data via MOSART to help with content chapterisation. We also think there is value in looking to the manual act of captioning as a separate workflow and data source for chapterisation of our linear output.
In partnership with BBC R&D, we are looking at how we could use Captions output to train our SpeakerID dataset (see the Transcriptor project).
If you want to get in touch, send us a tweet @BBC_News_Labs
Results
- The accuracy of the prototype was very impressive, but it was not considered a priority for transfer into production as a fully supported BBC tool.
Similar projects
View all improving workflows projectsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



