Aims
If we extract names from BBC News articles then could we make a list of the most-used contributors?
The BBC is committed to impartiality and that means ensuring that we have a wide range of people and opinions reflected in our output. News Labs looked at if we could build a prototype to help with that.

We focussed on providing reliable data about who is quoted in news stories. We wanted to do that without asking journalists to compile lists of everyone they’ve used in every story as that would have added to workloads.
We decided to create a prototype that would take in BBC News online stories from a specific section, be it the business desk or the health desk, over a time frame and return a list of the most-used contributors and then email that list to editors. We called it the Contributors prototype.
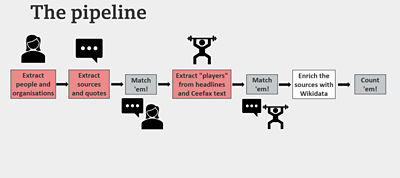
How we built a rapid prototype
We took the text from news articles and put it through a BBC tool called Citron to extract quotes and who said them.
This wasn’t enough, so we added a few more stages.
Our prototype was listing multiple references of a person as if it were different people.
So then we added the open-source software Fuzzball to match up various references to the same person.
This still wasn’t enough. Our prototype was giving us a list with names of people involved in the story, when what we wanted was the names of people that the journalists had chosen to quote.
So we used Amazon’s natural-language processing service Comprehend to identify the person the news story was about. We asked it to identify proper nouns and filter out names that were mentioned in the headline and summary. We also asked it to filter out people who were mentioned above a certain number of times.
As an extra, we used the Wikimedia Foundation’s data storage repository Wikidata to add more information about contributors, such as their age.
We then built a feature that counts the names so that we could discover how many times a contributor had been quoted in that time period.
Finally, we automatically generated an email for editors with a list of the most-used contributors.
What we found
The first few times we ran BBC News articles through the Contributors prototype, the list it generated wasn’t reliable.

The list included lots of additional meaningless data. The Local Democracy Reporting Service was quoted in 10 stories. But it is a news agency whose purpose is to provide impartial coverage of local authorities in the UK and not a contributor of the sort we had in mind.
Other meaningless data included listing “the trust”, “ministers” or “the party” as contributors.
The prototype didn’t effectively match multiple references to one individual. It didn’t spot that “Sir Keir”, “Labour leader Sir Keir Starmer” and “Sir Keir Starmer” were all the same person. Nor did it detect when the story was about him, rather than using him as a contributor, and filter his name out. The prototype, however, did spot when the story was about the Prime Minister, Boris Johnson, and filtered him out of the list. This meant that our data was potentially misleading.
New tools
We replaced some parts of our prototype to see if we could get more useful results.
Instead of Citron, Fuzzball and Amazon Comprehend, we tried out a tool made by the artificial intelligence laboratory OpenAI.
We tried to use Open AI’s GTP-3 - which stands for generative pre-training.
But we found, after multiple attempts, that GTP-3’s output was also unreliable.
Results
- The prototype needs refinement.
Team




Similar projects
View all structured journalism projectsBBC News Labs
-

News
Insights into our latest projects and ways of working -

Projects
We explore how new tools and formats affect how news is found and reported -

About
About BBC News Labs and how you can get involved -

Follow us on X
Formerly known as Twitter



